Khi API không làm được việc này, bạn luôn có thể khai thác HTML, và Rust có thể giúp bạn làm việc tìm nạp dữ liệu cho web.

Web scraping hay khai thác dữ liệu là một kỹ thuật phổ biến, nhanh chóng và hiệu quả để thu thập dữ liệu lớn từ các trang web. Nếu thiếu AI, web scraping có thể là phương pháp tiếp cận tốt nhất.
Tốc độ và an toàn bộ nhớ của Rust biến ngôn ngữ này trở thành lựa chọn lý tưởng trong việc xây dựng các trình khai thác dữ liệu web. Rust là “ngôi nhà” chứa nhiều thư viện trích xuất dữ liệu và phân tích cú pháp mạnh mẽ. Khả năng xử lý lỗi chuyên nghiệp của nó hữu ích trong việc thu thập dữ liệu web hiệu quả & đáng tin cậy.
Khai thác dữ liệu web trong Rust
Nhiều thư viện phổ biến hỗ trợ khai thác dữ liệu web trong Rust, bao gồm reqwest, scraper, select, và html5ever. Phần lớn lập trình viên Rust đều kết hợp tính năng từ reqwest và scraper cho khai thác web của họ.
Thư viện reqwest cung cấp chức năng tạo truy vấn HTTP cho server web. Reqwest được xây dựng trên crate hyper trong chuyển một API cấp cao cho các tính năng HTTP chuẩn.
Scraper là một thư viện khai thác web mạnh, phân tích tài liệu HTML và XML, đồng thời trích xuất dữ liệu bằng các bộ chọn CSS & biểu thức XPath.
Sau khi tạo một dự án Rust mới bằng lệnh cargo new, thêm crate reqwest & scraper vào các phần phụ thuộc của file cargo.toml:
[dependencies]
reqwest = {version = "0.11", features = ["blocking"]}
scraper = "0.12.0"Bạn sẽ dùng reqwest để gửi truy vấn HTTP và scraper cho phân tích cú pháp.
Truy xuất trang web bằng Reqwest
Bạn sẽ gửi truy vấn nội dung của trang web trước khi phân tích nó để trích xuất dữ liệu cụ thể.
Bạn có thể gửi truy vấn Get và xuất nguồn HTML của một trang bằng hàm text trên hàm get của thư viện reqwest:
fn retrieve_html() -> String {
let response = get("https://news.ycombinator.com").unwrap().text().unwrap();
return response;
}Hàm get gửi truy vấn tới trang web và hàm text trả về nội dung của HTML.
Phân tích HTML bằng Scraper
Hàm retrieve_html trả về nội dung của HTML. Bạn sẽ cần phần tích nó để xuất dữ liệu mong muốn.
Scraper cung cấp tính năng tương tác với HTML trong mô đun Html và Selector. Mô đun Html cho bạn tính năng phân tích tài liệu, còn mô đun Selector sẽ chọn phần tử cụ thể trong HTML.
Đây là cách bạn có thể xuất tất cả tiêu đề trên một trang:
use scraper::{Html, Selector};
fn main() {
let response = reqwest::blocking::get(
"https://news.ycombinator.com/").unwrap().text().unwrap();
// phân tích tài liệu HTM
let doc_body = Html::parse_document(&response);
// chọn phần tử chứa class titleline
let title = Selector::parse(".titleline").unwrap();
for title in doc_body.select(&title) {
let titles = title.text().collect::<Vec<_>>();
println!("{}", titles[0])
}
}Hàm parse_document của mô đun Html phân tích nội dung HTML, và Parse của mô đun Selector chọn các phần tử chứa bộ chọn CSS được chỉ định (ở đây là class titleline).
Vòng lặp for duyệt qua những phần tử này và in khối đầu tiên của text từ mỗi phần tử.
Đây là kết quả:
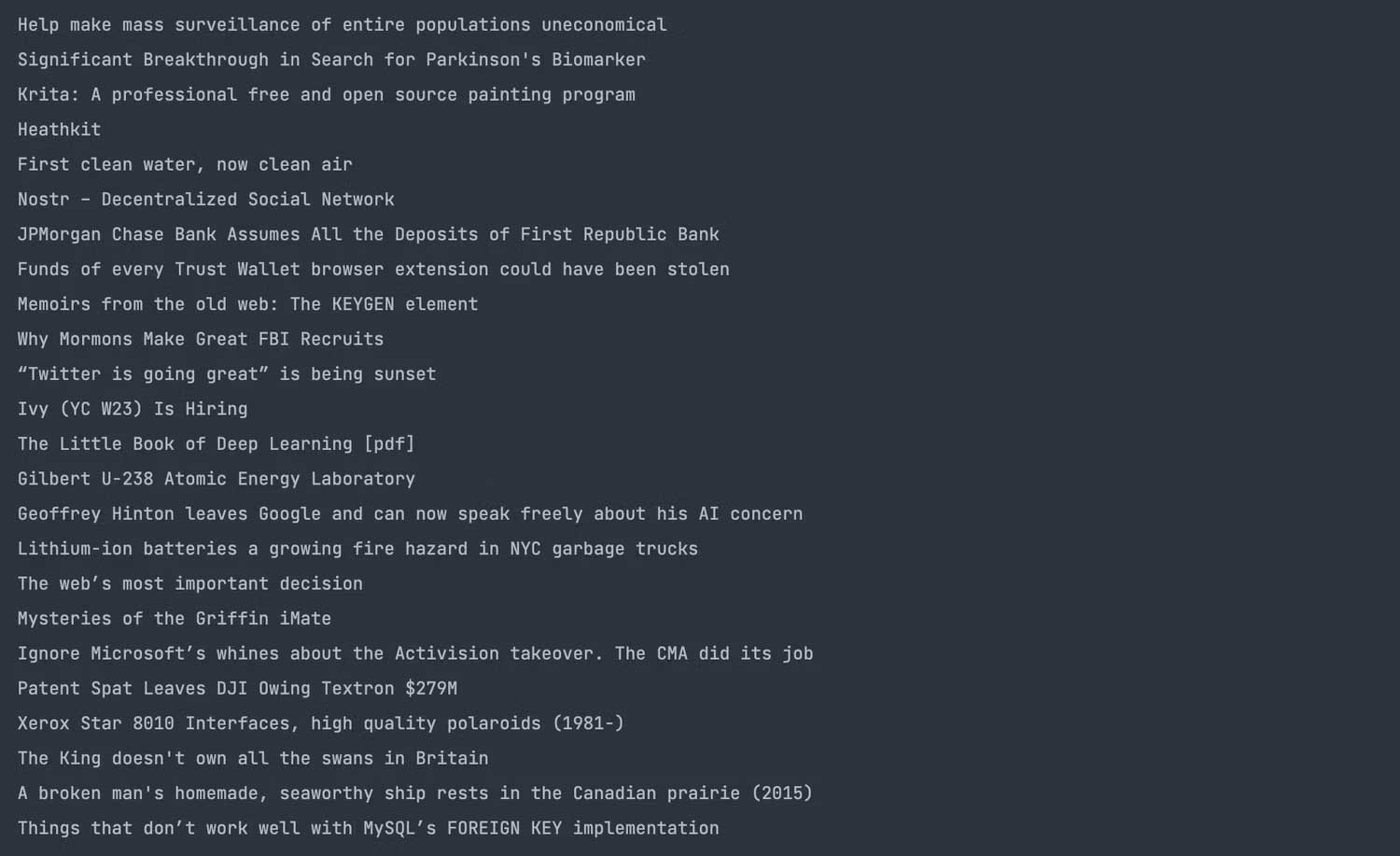
Chọn thuộc tính với Scraper
Để chọn một giá trị thuộc tính, xuất các phần tử được yêu cầu và dùng phương thức attr của phiên bản giá trị thẻ:
use reqwest::blocking::get;
use scraper::{Html, Selector};
fn main() {
let response = get("https://news.ycombinator.com").unwrap().text().unwrap();
let html_doc = Html::parse_document(&response);
let class_selector = Selector::parse(".titleline").unwrap();
for element in html_doc.select(&class_selector) {
let link_selector = Selector::parse("a").unwrap();
for link in element.select(&link_selector) {
if let Some(href) = link.value().attr("href") {
println!("{}", href);
}
}
}
}Sau khi chọn phần tử bằng class titleline bằng hàm parse, vòng lặp for sẽ duyệt qua chúng. Bên trong loop, code này tìm nạp các thẻ a và chọn thuộc tính href với thuộc tính attr.
Hàm main in những link này cùng kết quả như sau:

Trên đây là cách khai thác và tìm nạp dữ liệu web bằng Rust. Hi vọng bài viết hữu ích với các bạn.


























































